
ChatGPT ile sohbet ettiğinizde, Google'da arama yaptığınızda veya yapay zeka destekli bir uygulamayla karşılaştığınızda, aslında büyük dil modelleri olarak adlandırılan gelişmiş yapay zeka sistemleriyle etkileşime giriyorsunuz. Büyük Dil Modelleri (Large Language Models - LLM), son yıllarda yapay zeka alanında devrim yaratan ve günlük hayatımızın pek çok alanında kullanılan teknolojiler.
Bu yazıda, LLM'lerin ne olduğunu, nasıl çalıştıklarını ve neden bu kadar önemli olduklarını anlatacağım.
Büyük Dil Modeli nedir?

Büyük Dil Modelleri, makine öğrenmesi teknikleriyle eğitilmiş, insan dilini anlayan ve insan benzeri metinler üreten ileri düzey yapay zeka sistemler olarak tanımlanabilir. Bu modeller milyarlarca, hatta trilyonlarca kelime içeren devasa veri setleri üzerinde eğitilir.
İsmindeki "büyük" ifadesi, bu modellerin içerdiği parametre sayısına işaret eder. Parametreler, modelin davranışını belirleyen matematiksel değerlerdir ve bazı LLM'ler yüz milyarlarca veriden oluşur.
LLM'ler, dönüştürücü (transformer) olarak adlandırılan özel bir sinir ağı mimarisine dayanıyor. Bu mimari, 2017 yılında Google araştırmacıları tarafından "Attention is All You Need" başlıklı makalede tanıtıldı. Dönüştürücüler, metin verilerini işleyip analiz ederek kelimelerin ve cümlelerin anlamını çıkarabilir, kelimeler arasındaki ilişkileri kavrayabilir.
Nasıl çalışıyor?
LLM'lerin çalışma prensibi, görünenden çok daha karmaşık olmakla birlikte temel mantığı şöyle özetlenebilir: Öncelikle internet kaynakları, kitaplar, makaleler ve veritabanları gibi çok çeşitli kaynaklardan toplanan devasa miktarda metin verisi temizlenir ve işlenir. Bu metinler daha sonra "token" adı verilen küçük parçalara bölünür.
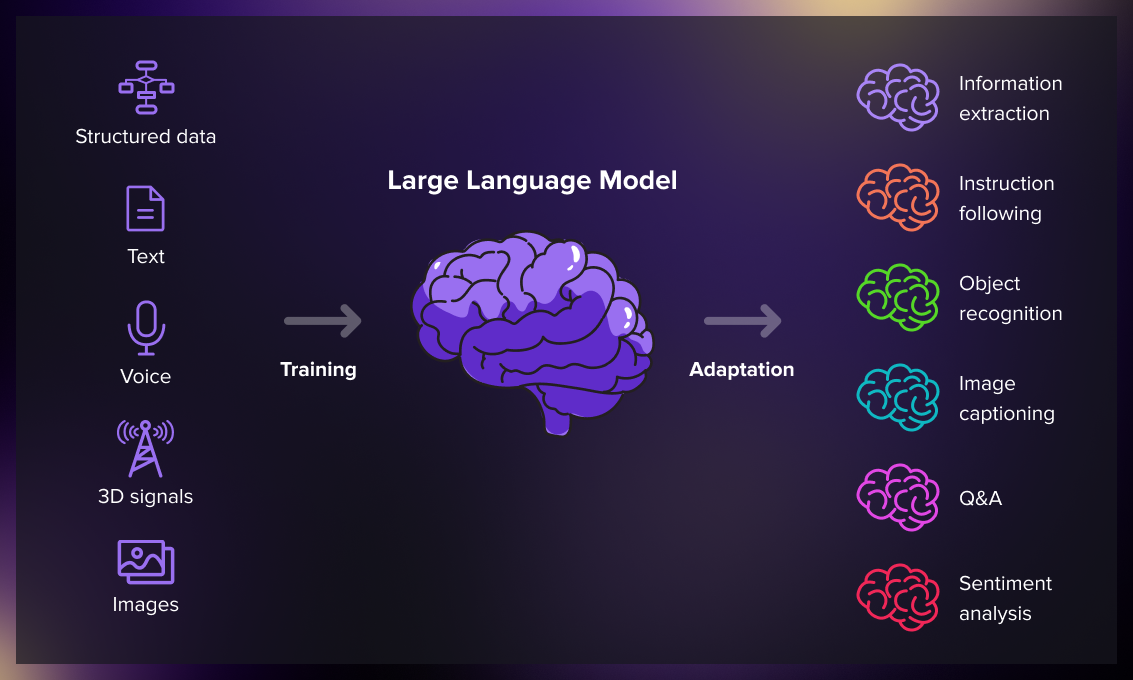
Model, denetimsiz öğrenme yöntemiyle eğitilirken, cümlelerdeki bazı kelimeler kasıtlı olarak gizlenir ve modelden bu eksik kelimeleri tahmin etmesi istenir. Binlerce kez tekrarlanan bu egzersizler sayesinde model, hangi kelimelerin hangi kelimelerden sonra gelme olasılığının yüksek olduğunu öğrenir. LLM'lerin temel çalışma prensibi tam da bu olasılık hesaplamalarına dayanır.
Örneğin "Türkiye'nin başkenti..." cümlesinden sonra "Ankara" kelimesinin gelme olasılığı çok yüksektir çünkü eğitim verilerinde bu kombinasyon sıklıkla tekrarlanmıştır. Dönüştürücü mimarisi sayesinde model, bir cümledeki farklı kelimelerin birbirleriyle olan ilişkilerini de anlayabilir ve benzer anlamlara sahip kelimeleri vektör uzayında birbirlerine yakın konumlandırır.
Ancak model yanlış tahminler de yapabilir çünkü her zaman en yüksek olasılıklı kelime doğru kelime olmayabilir. İşte bu nedenle LLM'ler bazen gerçek olmayan bilgileri sanki doğruymuş gibi güvenle sunabilir. Bu duruma da "yapay zeka halüsinasyonu" diyoruz.

Ne işe yarıyor?
Büyük Dil Modelleri, yapay zeka teknolojisinin en etkileyici uygulamalarından biri olarak karşımıza çıkıyor. Metin üretimi, çeviri, soru cevaplama ve daha pek çok alanda devrim yaratan bu modeller, hayatımızı kolaylaştırıyor ancak beraberinde önemli riskler de taşıyor. LLM'lerin doğru bilgi vermek yerine olası yanıtlar üretmeye odaklandığını, halüsinasyon yapabildiğini ve dezenformasyonun yayılmasını hızlandırabildiğini unutmamak gerek.
Bu nedenle, LLM'leri kullanırken eleştirel düşünmeyi elden bırakmamak, ürettikleri bilgileri mutlaka doğrulamak ve bu araçları bir karar verici değil yardımcı olarak görmek şart.
Daha önceki yazılarımızda da vurguladığımız gibi, yapay zeka araçları bilgi almak için kullanılırken "şüphe kasını" çalıştırmak, kamunun doğru bilgiye erişim hakkını korumak açısından kritik önem taşıyor.
Büyük dil modelleri insanlık için muazzam fırsatlar sunarken, bu fırsatlardan sağlıklı bir şekilde yararlanabilmek için teknolojinin sınırlarını ve risklerini anlamak zorundayız. Dijital okuryazarlık ve medya okuryazarlığı becerileri, LLM çağında her zamankinden daha önemli.



















